Flows¶
Flows are the most central Prefect object. A flow is a container for workflow logic as-code and allows users to configure how their workflows behave. Flows are defined as Python functions, and any Python function is eligible to be a flow.
Flows overview¶
Flows can be thought of as special types of functions. They can take inputs, perform work, and return an output.
In fact, you can turn any function into a Prefect flow by adding the @flow decorator.
When a function becomes a flow, its behavior changes, giving it the following advantages:
- Every invocation of this function is tracked and all state transitions are reported to the API, allowing observation of flow execution.
- Input arguments are automatically type checked and coerced to the appropriate types.
- Retries can be performed on failure.
- Timeouts can be enforced to prevent unintentional, long-running workflows.
Flows also take advantage of automatic Prefect logging to capture details about flow runs such as run time and final state.
Flows can include calls to tasks as well as to other flows, which Prefect calls "subflows" in this context. Flows may be defined within modules and imported for use as subflows in your flow definitions.
Deployments elevate individual workflows from functions that you call manually to API-managed entities.
Tasks must be called from flows
All tasks must be called from within a flow. Tasks may not be called from other tasks.
Flow runs¶
A flow run represents a single execution of the flow.
You can create a flow run by calling the flow manually. For example, by running a Python script or importing the flow into an interactive session and calling it.
You can also create a flow run by:
- Using external schedulers such as
cronto invoke a flow function - Creating a deployment on Prefect Cloud or a locally run Prefect server.
- Creating a flow run for the deployment via a schedule, the Prefect UI, or the Prefect API.
However you run the flow, the Prefect API monitors the flow run, capturing flow run state for observability.
When you run a flow that contains tasks or additional flows, Prefect will track the relationship of each child run to the parent flow run.
Writing flows¶
The @flow decorator is used to designate a flow:
from prefect import flow
@flow
def my_flow():
return
There are no rigid rules for what code you include within a flow definition - all valid Python is acceptable.
Flows are uniquely identified by name. You can provide a name parameter value for the flow.
If you don't provide a name, Prefect uses the flow function name.
@flow(name="My Flow")
def my_flow():
return
Flows can call tasks to allow Prefect to orchestrate and track more granular units of work:
from prefect import flow, task
@task
def print_hello(name):
print(f"Hello {name}!")
@flow(name="Hello Flow")
def hello_world(name="world"):
print_hello(name)
Flows and tasks
There's nothing stopping you from putting all of your code in a single flow function — Prefect will happily run it!
However, organizing your workflow code into smaller flow and task units lets you take advantage of Prefect features like retries, more granular visibility into runtime state, the ability to determine final state regardless of individual task state, and more.
In addition, if you put all of your workflow logic in a single flow function and any line of code fails, the entire flow will fail and must be retried from the beginning. This can be avoided by breaking up the code into multiple tasks.
You may call any number of other tasks, subflows, and even regular Python functions within your flow. You can pass parameters to your flow function that will be used elsewhere in the workflow, and Prefect will report on the progress and final state of any invocation.
Prefect encourages "small tasks" — each one should represent a single logical step of your workflow. This allows Prefect to better contain task failures.
Flow settings¶
Flows allow a great deal of configuration by passing arguments to the decorator. Flows accept the following optional settings.
| Argument | Description |
|---|---|
description |
An optional string description for the flow. If not provided, the description will be pulled from the docstring for the decorated function. |
name |
An optional name for the flow. If not provided, the name will be inferred from the function. |
retries |
An optional number of times to retry on flow run failure. |
retry_delay_seconds |
An optional number of seconds to wait before retrying the flow after failure. This is only applicable if retries is nonzero. |
flow_run_name |
An optional name to distinguish runs of this flow; this name can be provided as a string template with the flow's parameters as variables; this name can also be provided as a function that returns a string. |
task_runner |
An optional task runner to use for task execution within the flow when you .submit() tasks. If not provided and you .submit() tasks, the ConcurrentTaskRunner will be used. |
timeout_seconds |
An optional number of seconds indicating a maximum runtime for the flow. If the flow exceeds this runtime, it will be marked as failed. Flow execution may continue until the next task is called. |
validate_parameters |
Boolean indicating whether parameters passed to flows are validated by Pydantic. Default is True. |
version |
An optional version string for the flow. If not provided, we will attempt to create a version string as a hash of the file containing the wrapped function. If the file cannot be located, the version will be null. |
For example, you can provide a name value for the flow. Here we've also used the optional description argument and specified a non-default task runner.
from prefect import flow
from prefect.task_runners import SequentialTaskRunner
@flow(name="My Flow",
description="My flow using SequentialTaskRunner",
task_runner=SequentialTaskRunner())
def my_flow():
return
You can also provide the description as the docstring on the flow function.
@flow(name="My Flow",
task_runner=SequentialTaskRunner())
def my_flow():
"""My flow using SequentialTaskRunner"""
return
You can distinguish runs of this flow by providing a flow_run_name.
This setting accepts a string that can optionally contain templated references to the parameters of your flow.
The name will be formatted using Python's standard string formatting syntax as can be seen here:
import datetime
from prefect import flow
@flow(flow_run_name="{name}-on-{date:%A}")
def my_flow(name: str, date: datetime.datetime):
pass
# creates a flow run called 'marvin-on-Thursday'
my_flow(name="marvin", date=datetime.datetime.now(datetime.timezone.utc))
Additionally this setting also accepts a function that returns a string for the flow run name:
import datetime
from prefect import flow
def generate_flow_run_name():
date = datetime.datetime.now(datetime.timezone.utc)
return f"{date:%A}-is-a-nice-day"
@flow(flow_run_name=generate_flow_run_name)
def my_flow(name: str):
pass
# creates a flow run called 'Thursday-is-a-nice-day'
if __name__ == "__main__":
my_flow(name="marvin")
If you need access to information about the flow, use the prefect.runtime module. For example:
from prefect import flow
from prefect.runtime import flow_run
def generate_flow_run_name():
flow_name = flow_run.flow_name
parameters = flow_run.parameters
name = parameters["name"]
limit = parameters["limit"]
return f"{flow_name}-with-{name}-and-{limit}"
@flow(flow_run_name=generate_flow_run_name)
def my_flow(name: str, limit: int = 100):
pass
# creates a flow run called 'my-flow-with-marvin-and-100'
if __name__ == "__main__":
my_flow(name="marvin")
Note that validate_parameters will check that input values conform to the annotated types on the function.
Where possible, values will be coerced into the correct type. For example, if a parameter is defined as x: int and "5" is passed, it will be resolved to 5.
If set to False, no validation will be performed on flow parameters.
Separating logic into tasks¶
The simplest workflow is just a @flow function that does all the work of the workflow.
from prefect import flow
@flow(name="Hello Flow")
def hello_world(name="world"):
print(f"Hello {name}!")
if __name__ == "__main__":
hello_world("Marvin")
When you run this flow, you'll see output like the following:
$ python hello.py
15:11:23.594 | INFO | prefect.engine - Created flow run 'benevolent-donkey' for flow 'hello-world'
15:11:23.594 | INFO | Flow run 'benevolent-donkey' - Using task runner 'ConcurrentTaskRunner'
Hello Marvin!
15:11:24.447 | INFO | Flow run 'benevolent-donkey' - Finished in state Completed()
A better practice is to create @task functions that do the specific work of your flow, and use your @flow function as the conductor that orchestrates the flow of your application:
from prefect import flow, task
@task(name="Print Hello")
def print_hello(name):
msg = f"Hello {name}!"
print(msg)
return msg
@flow(name="Hello Flow")
def hello_world(name="world"):
message = print_hello(name)
if __name__ == "__main__":
hello_world("Marvin")
When you run this flow, you'll see the following output, which illustrates how the work is encapsulated in a task run.
$ python hello.py
15:15:58.673 | INFO | prefect.engine - Created flow run 'loose-wolverine' for flow 'Hello Flow'
15:15:58.674 | INFO | Flow run 'loose-wolverine' - Using task runner 'ConcurrentTaskRunner'
15:15:58.973 | INFO | Flow run 'loose-wolverine' - Created task run 'Print Hello-84f0fe0e-0' for task 'Print Hello'
Hello Marvin!
15:15:59.037 | INFO | Task run 'Print Hello-84f0fe0e-0' - Finished in state Completed()
15:15:59.568 | INFO | Flow run 'loose-wolverine' - Finished in state Completed('All states completed.')
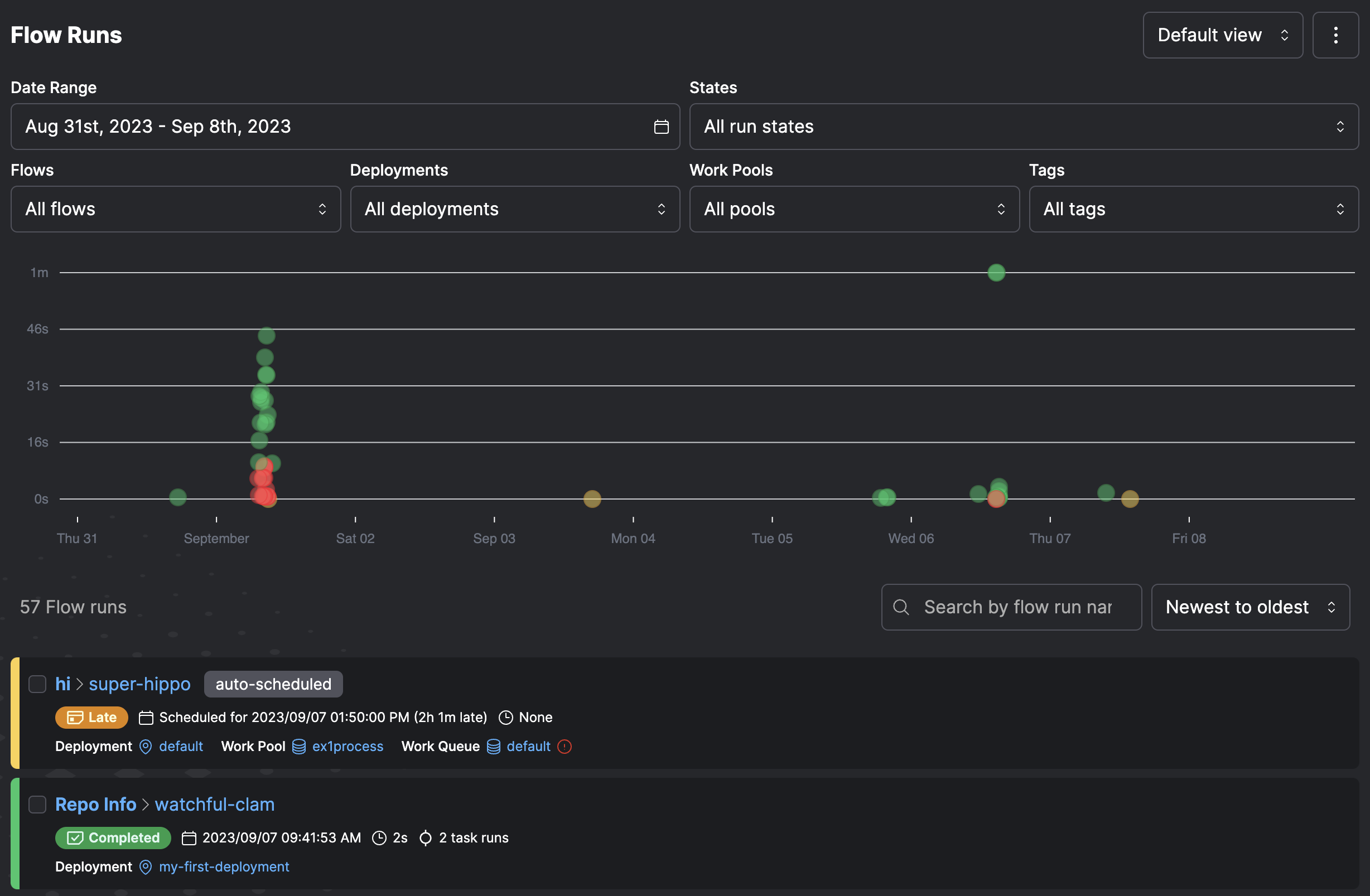
Visualizing flow structure¶
You can get a quick sense of the structure of your flow using the .visualize() method on your flow. Calling this method will attempt to produce a schematic diagram of your flow and tasks without actually running your flow code.
Functions and code not inside of flows or tasks will still be run when calling .visualize(). This may have unintended consequences. Place your code into tasks to avoid unintended execution.
To use the visualize() method, Graphviz must be installed and on your PATH. Please install Graphviz from http://www.graphviz.org/download/. And note: just installing the graphviz python package is not sufficient.
from prefect import flow, task
@task(name="Print Hello")
def print_hello(name):
msg = f"Hello {name}!"
print(msg)
return msg
@task(name="Print Hello Again")
def print_hello_again(name):
msg = f"Hello {name}!"
print(msg)
return msg
@flow(name="Hello Flow")
def hello_world(name="world"):
message = print_hello(name)
message2 = print_hello_again(message)
if __name__ == "__main__":
hello_world.visualize()
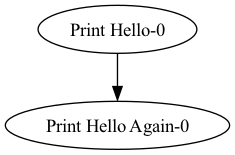
Prefect cannot automatically produce a schematic for dynamic workflows, such as those with loops or if/else control flow.
In this case, you can provide tasks with mock return values for use in the visualize() call.
from prefect import flow, task
@task(viz_return_value=[4])
def get_list():
return [1, 2, 3]
@task
def append_one(n):
return n.append(6)
@flow
def viz_return_value_tracked():
l = get_list()
for num in range(3):
l.append(5)
append_one(l)
if __name__ == "__main__":
viz_return_value_tracked.visualize()
Composing flows¶
A subflow run is created when a flow function is called inside the execution of another flow. The primary flow is the "parent" flow. The flow created within the parent is the "child" flow or "subflow."
Subflow runs behave like normal flow runs. There is a full representation of the flow run in the backend as if it had been called separately. When a subflow starts, it will create a new task runner for tasks within the subflow. When the subflow completes, the task runner is shut down.
Subflows will block execution of the parent flow until completion. However, asynchronous subflows can be run concurrently by using AnyIO task groups or asyncio.gather.
Subflows differ from normal flows in that they will resolve any passed task futures into data. This allows data to be passed from the parent flow to the child easily.
The relationship between a child and parent flow is tracked by creating a special task run in the parent flow. This task run will mirror the state of the child flow run.
A task that represents a subflow will be annotated as such in its state_details via the presence of a child_flow_run_id field.
A subflow can be identified via the presence of a parent_task_run_id on state_details.
You can define multiple flows within the same file. Whether running locally or via a deployment, you must indicate which flow is the entrypoint for a flow run.
Cancelling subflow runs
Inline subflow runs, specifically those created without run_deployment, cannot be cancelled without cancelling their parent flow run.
If you may need to cancel a subflow run independent of its parent flow run, we recommend deploying it separately and starting it using the run_deployment function.
from prefect import flow, task
@task(name="Print Hello")
def print_hello(name):
msg = f"Hello {name}!"
print(msg)
return msg
@flow(name="Subflow")
def my_subflow(msg):
print(f"Subflow says: {msg}")
@flow(name="Hello Flow")
def hello_world(name="world"):
message = print_hello(name)
my_subflow(message)
if __name__ == "__main__":
hello_world("Marvin")
You can also define flows or tasks in separate modules and import them for usage. For example, here's a simple subflow module:
from prefect import flow, task
@flow(name="Subflow")
def my_subflow(msg):
print(f"Subflow says: {msg}")
Here's a parent flow that imports and uses my_subflow() as a subflow:
from prefect import flow, task
from subflow import my_subflow
@task(name="Print Hello")
def print_hello(name):
msg = f"Hello {name}!"
print(msg)
return msg
@flow(name="Hello Flow")
def hello_world(name="world"):
message = print_hello(name)
my_subflow(message)
hello_world("Marvin")
Running the hello_world() flow (in this example from the file hello.py) creates a flow run like this:
$ python hello.py
15:19:21.651 | INFO | prefect.engine - Created flow run 'daft-cougar' for flow 'Hello Flow'
15:19:21.651 | INFO | Flow run 'daft-cougar' - Using task runner 'ConcurrentTaskRunner'
15:19:21.945 | INFO | Flow run 'daft-cougar' - Created task run 'Print Hello-84f0fe0e-0' for task 'Print Hello'
Hello Marvin!
15:19:22.055 | INFO | Task run 'Print Hello-84f0fe0e-0' - Finished in state Completed()
15:19:22.107 | INFO | Flow run 'daft-cougar' - Created subflow run 'ninja-duck' for flow 'Subflow'
Subflow says: Hello Marvin!
15:19:22.794 | INFO | Flow run 'ninja-duck' - Finished in state Completed()
15:19:23.215 | INFO | Flow run 'daft-cougar' - Finished in state Completed('All states completed.')
Subflows or tasks?
In Prefect you can call tasks or subflows to do work within your workflow, including passing results from other tasks to your subflow. So a common question is:
"When should I use a subflow instead of a task?"
We recommend writing tasks that do a discrete, specific piece of work in your workflow: calling an API, performing a database operation, analyzing or transforming a data point. Prefect tasks are well suited to parallel or distributed execution using distributed computation frameworks such as Dask or Ray. For troubleshooting, the more granular you create your tasks, the easier it is to find and fix issues should a task fail.
Subflows enable you to group related tasks within your workflow. Here are some scenarios where you might choose to use a subflow rather than calling tasks individually:
- Observability: Subflows, like any other flow run, have first-class observability within the Prefect UI and Prefect Cloud. You'll see subflow status in the Flow Runs dashboard rather than having to dig down into the tasks within a specific flow run. See Final state determination for some examples of leveraging task state within flows.
- Conditional flows: If you have a group of tasks that run only under certain conditions, you can group them within a subflow and conditionally run the subflow rather than each task individually.
- Parameters: Flows have first-class support for parameterization, making it easy to run the same group of tasks in different use cases by simply passing different parameters to the subflow in which they run.
- Task runners: Subflows enable you to specify the task runner used for tasks within the flow. For example, if you want to optimize parallel execution of certain tasks with Dask, you can group them in a subflow that uses the Dask task runner. You can use a different task runner for each subflow.
Parameters¶
Flows can be called with both positional and keyword arguments. These arguments are resolved at runtime into a dictionary of parameters mapping name to value. These parameters are stored by the Prefect orchestration engine on the flow run object.
Prefect API requires keyword arguments
When creating flow runs from the Prefect API, parameter names must be specified when overriding defaults — they cannot be positional.
Type hints provide an easy way to enforce typing on your flow parameters via pydantic. This means any pydantic model used as a type hint within a flow will be coerced automatically into the relevant object type:
from prefect import flow
from pydantic import BaseModel
class Model(BaseModel):
a: int
b: float
c: str
@flow
def model_validator(model: Model):
print(model)
Note that parameter values can be provided to a flow via API using a deployment. Flow run parameters sent to the API on flow calls are coerced to a serializable form. Type hints on your flow functions provide you a way of automatically coercing JSON provided values to their appropriate Python representation.
For example, to automatically convert something to a datetime:
from prefect import flow
from datetime import datetime
@flow
def what_day_is_it(date: datetime = None):
if date is None:
date = datetime.now(timezone.utc)
print(f"It was {date.strftime('%A')} on {date.isoformat()}")
if __name__ == "__main__":
what_day_is_it("2021-01-01T02:00:19.180906")
When you run this flow, you'll see the following output:
It was Friday on 2021-01-01T02:00:19.180906
Parameters are validated before a flow is run.
If a flow call receives invalid parameters, a flow run is created in a Failed state.
If a flow run for a deployment receives invalid parameters, it will move from a Pending state to a Failed without entering a Running state.
Flow run parameters cannot exceed 512kb in size
Final state determination¶
Prerequisite
Read the documentation about states before proceeding with this section.
The final state of the flow is determined by its return value. The following rules apply:
- If an exception is raised directly in the flow function, the flow run is marked as failed.
- If the flow does not return a value (or returns
None), its state is determined by the states of all of the tasks and subflows within it. - If any task run or subflow run failed, then the final flow run state is marked as
FAILED. - If any task run was cancelled, then the final flow run state is marked as
CANCELLED. - If a flow returns a manually created state, it is used as the state of the final flow run. This allows for manual determination of final state.
- If the flow run returns any other object, then it is marked as completed.
The following examples illustrate each of these cases:
Raise an exception¶
If an exception is raised within the flow function, the flow is immediately marked as failed.
from prefect import flow
@flow
def always_fails_flow():
raise ValueError("This flow immediately fails")
if __name__ == "__main__":
always_fails_flow()
Running this flow produces the following result:
22:22:36.864 | INFO | prefect.engine - Created flow run 'acrid-tuatara' for flow 'always-fails-flow'
22:22:36.864 | INFO | Flow run 'acrid-tuatara' - Starting 'ConcurrentTaskRunner'; submitted tasks will be run concurrently...
22:22:37.060 | ERROR | Flow run 'acrid-tuatara' - Encountered exception during execution:
Traceback (most recent call last):...
ValueError: This flow immediately fails
Return none¶
A flow with no return statement is determined by the state of all of its task runs.
from prefect import flow, task
@task
def always_fails_task():
raise ValueError("I fail successfully")
@task
def always_succeeds_task():
print("I'm fail safe!")
return "success"
@flow
def always_fails_flow():
always_fails_task.submit().result(raise_on_failure=False)
always_succeeds_task()
if __name__ == "__main__":
always_fails_flow()
Running this flow produces the following result:
18:32:05.345 | INFO | prefect.engine - Created flow run 'auburn-lionfish' for flow 'always-fails-flow'
18:32:05.346 | INFO | Flow run 'auburn-lionfish' - Starting 'ConcurrentTaskRunner'; submitted tasks will be run concurrently...
18:32:05.582 | INFO | Flow run 'auburn-lionfish' - Created task run 'always_fails_task-96e4be14-0' for task 'always_fails_task'
18:32:05.582 | INFO | Flow run 'auburn-lionfish' - Submitted task run 'always_fails_task-96e4be14-0' for execution.
18:32:05.610 | ERROR | Task run 'always_fails_task-96e4be14-0' - Encountered exception during execution:
Traceback (most recent call last):
...
ValueError: I fail successfully
18:32:05.638 | ERROR | Task run 'always_fails_task-96e4be14-0' - Finished in state Failed('Task run encountered an exception.')
18:32:05.658 | INFO | Flow run 'auburn-lionfish' - Created task run 'always_succeeds_task-9c27db32-0' for task 'always_succeeds_task'
18:32:05.659 | INFO | Flow run 'auburn-lionfish' - Executing 'always_succeeds_task-9c27db32-0' immediately...
I'm fail safe!
18:32:05.703 | INFO | Task run 'always_succeeds_task-9c27db32-0' - Finished in state Completed()
18:32:05.730 | ERROR | Flow run 'auburn-lionfish' - Finished in state Failed('1/2 states failed.')
Traceback (most recent call last):
...
ValueError: I fail successfully
Return a future¶
If a flow returns one or more futures, the final state is determined based on the underlying states.
from prefect import flow, task
@task
def always_fails_task():
raise ValueError("I fail successfully")
@task
def always_succeeds_task():
print("I'm fail safe!")
return "success"
@flow
def always_succeeds_flow():
x = always_fails_task.submit().result(raise_on_failure=False)
y = always_succeeds_task.submit(wait_for=[x])
return y
if __name__ == "__main__":
always_succeeds_flow()
Running this flow produces the following result — it succeeds because it returns the future of the task that succeeds:
18:35:24.965 | INFO | prefect.engine - Created flow run 'whispering-guan' for flow 'always-succeeds-flow'
18:35:24.965 | INFO | Flow run 'whispering-guan' - Starting 'ConcurrentTaskRunner'; submitted tasks will be run concurrently...
18:35:25.204 | INFO | Flow run 'whispering-guan' - Created task run 'always_fails_task-96e4be14-0' for task 'always_fails_task'
18:35:25.205 | INFO | Flow run 'whispering-guan' - Submitted task run 'always_fails_task-96e4be14-0' for execution.
18:35:25.232 | ERROR | Task run 'always_fails_task-96e4be14-0' - Encountered exception during execution:
Traceback (most recent call last):
...
ValueError: I fail successfully
18:35:25.265 | ERROR | Task run 'always_fails_task-96e4be14-0' - Finished in state Failed('Task run encountered an exception.')
18:35:25.289 | INFO | Flow run 'whispering-guan' - Created task run 'always_succeeds_task-9c27db32-0' for task 'always_succeeds_task'
18:35:25.289 | INFO | Flow run 'whispering-guan' - Submitted task run 'always_succeeds_task-9c27db32-0' for execution.
I'm fail safe!
18:35:25.335 | INFO | Task run 'always_succeeds_task-9c27db32-0' - Finished in state Completed()
18:35:25.362 | INFO | Flow run 'whispering-guan' - Finished in state Completed('All states completed.')
Return multiple states or futures¶
If a flow returns a mix of futures and states, the final state is determined by resolving all futures to states, then determining if any of the states are not COMPLETED.
from prefect import task, flow
@task
def always_fails_task():
raise ValueError("I am bad task")
@task
def always_succeeds_task():
return "foo"
@flow
def always_succeeds_flow():
return "bar"
@flow
def always_fails_flow():
x = always_fails_task()
y = always_succeeds_task()
z = always_succeeds_flow()
return x, y, z
Running this flow produces the following result.
It fails because one of the three returned futures failed.
Note that the final state is Failed, but the states of each of the returned futures is included in the flow state:
20:57:51.547 | INFO | prefect.engine - Created flow run 'impartial-gorilla' for flow 'always-fails-flow'
20:57:51.548 | INFO | Flow run 'impartial-gorilla' - Using task runner 'ConcurrentTaskRunner'
20:57:51.645 | INFO | Flow run 'impartial-gorilla' - Created task run 'always_fails_task-58ea43a6-0' for task 'always_fails_task'
20:57:51.686 | INFO | Flow run 'impartial-gorilla' - Created task run 'always_succeeds_task-c9014725-0' for task 'always_succeeds_task'
20:57:51.727 | ERROR | Task run 'always_fails_task-58ea43a6-0' - Encountered exception during execution:
Traceback (most recent call last):...
ValueError: I am bad task
20:57:51.787 | INFO | Task run 'always_succeeds_task-c9014725-0' - Finished in state Completed()
20:57:51.808 | INFO | Flow run 'impartial-gorilla' - Created subflow run 'unbiased-firefly' for flow 'always-succeeds-flow'
20:57:51.884 | ERROR | Task run 'always_fails_task-58ea43a6-0' - Finished in state Failed('Task run encountered an exception.')
20:57:52.438 | INFO | Flow run 'unbiased-firefly' - Finished in state Completed()
20:57:52.811 | ERROR | Flow run 'impartial-gorilla' - Finished in state Failed('1/3 states failed.')
Failed(message='1/3 states failed.', type=FAILED, result=(Failed(message='Task run encountered an exception.', type=FAILED, result=ValueError('I am bad task'), task_run_id=5fd4c697-7c4c-440d-8ebc-dd9c5bbf2245), Completed(message=None, type=COMPLETED, result='foo', task_run_id=df9b6256-f8ac-457c-ba69-0638ac9b9367), Completed(message=None, type=COMPLETED, result='bar', task_run_id=cfdbf4f1-dccd-4816-8d0f-128750017d0c)), flow_run_id=6d2ec094-001a-4cb0-a24e-d2051db6318d)
Returning multiple states
When returning multiple states, they must be contained in a set, list, or tuple.
If other collection types are used, the result of the contained states will not be checked.
Return a manual state¶
If a flow returns a manually created state, the final state is determined based on the return value.
from prefect import task, flow
from prefect.states import Completed, Failed
@task
def always_fails_task():
raise ValueError("I fail successfully")
@task
def always_succeeds_task():
print("I'm fail safe!")
return "success"
@flow
def always_succeeds_flow():
x = always_fails_task.submit()
y = always_succeeds_task.submit()
if y.result() == "success":
return Completed(message="I am happy with this result")
else:
return Failed(message="How did this happen!?")
if __name__ == "__main__":
always_succeeds_flow()
Running this flow produces the following result.
18:37:42.844 | INFO | prefect.engine - Created flow run 'lavender-elk' for flow 'always-succeeds-flow'
18:37:42.845 | INFO | Flow run 'lavender-elk' - Starting 'ConcurrentTaskRunner'; submitted tasks will be run concurrently...
18:37:43.125 | INFO | Flow run 'lavender-elk' - Created task run 'always_fails_task-96e4be14-0' for task 'always_fails_task'
18:37:43.126 | INFO | Flow run 'lavender-elk' - Submitted task run 'always_fails_task-96e4be14-0' for execution.
18:37:43.162 | INFO | Flow run 'lavender-elk' - Created task run 'always_succeeds_task-9c27db32-0' for task 'always_succeeds_task'
18:37:43.163 | INFO | Flow run 'lavender-elk' - Submitted task run 'always_succeeds_task-9c27db32-0' for execution.
18:37:43.175 | ERROR | Task run 'always_fails_task-96e4be14-0' - Encountered exception during execution:
Traceback (most recent call last):
...
ValueError: I fail successfully
I'm fail safe!
18:37:43.217 | ERROR | Task run 'always_fails_task-96e4be14-0' - Finished in state Failed('Task run encountered an exception.')
18:37:43.236 | INFO | Task run 'always_succeeds_task-9c27db32-0' - Finished in state Completed()
18:37:43.264 | INFO | Flow run 'lavender-elk' - Finished in state Completed('I am happy with this result')
Return an object¶
If the flow run returns any other object, then it is marked as completed.
from prefect import task, flow
@task
def always_fails_task():
raise ValueError("I fail successfully")
@flow
def always_succeeds_flow():
always_fails_task().submit()
return "foo"
if __name__ == "__main__":
always_succeeds_flow()
Running this flow produces the following result.
21:02:45.715 | INFO | prefect.engine - Created flow run 'sparkling-pony' for flow 'always-succeeds-flow'
21:02:45.715 | INFO | Flow run 'sparkling-pony' - Using task runner 'ConcurrentTaskRunner'
21:02:45.816 | INFO | Flow run 'sparkling-pony' - Created task run 'always_fails_task-58ea43a6-0' for task 'always_fails_task'
21:02:45.853 | ERROR | Task run 'always_fails_task-58ea43a6-0' - Encountered exception during execution:
Traceback (most recent call last):...
ValueError: I am bad task
21:02:45.879 | ERROR | Task run 'always_fails_task-58ea43a6-0' - Finished in state Failed('Task run encountered an exception.')
21:02:46.593 | INFO | Flow run 'sparkling-pony' - Finished in state Completed()
Completed(message=None, type=COMPLETED, result='foo', flow_run_id=7240e6f5-f0a8-4e00-9440-a7b33fb51153)
Serving a flow¶
The simplest way to create a deployment for your flow is by calling its serve method.
This method creates a deployment for the flow and starts a long-running process that monitors for work from the Prefect server.
When work is found, it is executed within its own isolated subprocess.
from prefect import flow
@flow(log_prints=True)
def hello_world(name: str = "world", goodbye: bool = False):
print(f"Hello {name} from Prefect! 🤗")
if goodbye:
print(f"Goodbye {name}!")
if __name__ == "__main__":
# creates a deployment and stays running to monitor for work instructions generated on the server
hello_world.serve(name="my-first-deployment",
tags=["onboarding"],
parameters={"goodbye": True},
interval=60)
This interface provides all of the configuration needed for a deployment with no strong infrastructure requirements:
- schedules
- event triggers
- metadata such as tags and description
- default parameter values
Schedules are auto-paused on shutdown
By default, stopping the process running flow.serve will pause the schedule for the deployment (if it has one).
When running this in environments where restarts are expected use the pause_on_shutdown=False flag to prevent this behavior:
if __name__ == "__main__":
hello_world.serve(name="my-first-deployment",
tags=["onboarding"],
parameters={"goodbye": True},
pause_on_shutdown=False,
interval=60)
Serving multiple flows at once¶
You can take this further and serve multiple flows with the same process using the serve utility along with the to_deployment method of flows:
import time
from prefect import flow, serve
@flow
def slow_flow(sleep: int = 60):
"Sleepy flow - sleeps the provided amount of time (in seconds)."
time.sleep(sleep)
@flow
def fast_flow():
"Fastest flow this side of the Mississippi."
return
if __name__ == "__main__":
slow_deploy = slow_flow.to_deployment(name="sleeper", interval=45)
fast_deploy = fast_flow.to_deployment(name="fast")
serve(slow_deploy, fast_deploy)
The behavior and interfaces are identical to the single flow case.
Retrieve a flow from remote storage¶
Flows can be retrieved from remote storage using the flow.from_source method.
flow.from_source accepts a git repository URL and an entrypoint pointing to the flow to load from the repository:
from prefect import flow
my_flow = flow.from_source(
source="https://github.com/PrefectHQ/prefect.git",
entrypoint="flows/hello_world.py:hello"
)
if __name__ == "__main__":
my_flow()
16:40:33.818 | INFO | prefect.engine - Created flow run 'muscular-perch' for flow 'hello'
16:40:34.048 | INFO | Flow run 'muscular-perch' - Hello world!
16:40:34.706 | INFO | Flow run 'muscular-perch' - Finished in state Completed()
A flow entrypoint is the path to the file the flow is located in and the name of the flow function separated by a colon.
If you need additional configuration, such as specifying a private repository, you can provide a GitRepository instead of URL:
from prefect import flow
from prefect.runner.storage import GitRepository
from prefect.blocks.system import Secret
my_flow = flow.from_source(
source=GitRepository(
url="https://github.com/org/private-repo.git",
branch="dev",
credentials={
"access_token": Secret.load("github-access-token").get()
}
),
entrypoint="flows.py:my_flow"
)
if __name__ == "__main__":
my_flow()
You can serve loaded flows
Flows loaded from remote storage can be served using the same serve method as local flows:
from prefect import flow
if __name__ == "__main__":
flow.from_source(
source="https://github.com/org/repo.git",
entrypoint="flows.py:my_flow"
).serve(name="my-deployment")
When you serve a flow loaded from remote storage, the serving process will periodically poll your remote storage for updates to the flow's code. This pattern allows you to update your flow code without restarting the serving process.
Pausing or suspending a flow run¶
Prefect provides you with the ability to halt a flow run with two functions that are similar, but slightly different. When a flow run is paused, code execution is stopped and the process continues to run. When a flow run is suspended, code execution is stopped and so is the process.
Pausing a flow run¶
Prefect enables pausing an in-progress flow run for manual approval.
Prefect exposes this functionality via the pause_flow_run and resume_flow_run functions.
Timeouts
Paused flow runs time out after one hour by default.
After the timeout, the flow run will fail with a message saying it paused and never resumed.
You can specify a different timeout period in seconds using the timeout parameter.
Most simply, pause_flow_run can be called inside a flow:
from prefect import task, flow, pause_flow_run, resume_flow_run
@task
async def marvin_setup():
return "a raft of ducks walk into a bar..."
@task
async def marvin_punchline():
return "it's a wonder none of them ducked!"
@flow
async def inspiring_joke():
await marvin_setup()
await pause_flow_run(timeout=600) # pauses for 10 minutes
await marvin_punchline()
You can also implement conditional pauses:
from prefect import task, flow, pause_flow_run
@task
def task_one():
for i in range(3):
sleep(1)
print(i)
@flow(log_prints=True)
def my_flow():
terminal_state = task_one.submit(return_state=True)
if terminal_state.type == StateType.COMPLETED:
print("Task one succeeded! Pausing flow run..")
pause_flow_run(timeout=2)
else:
print("Task one failed. Skipping pause flow run..")
Calling this flow will block code execution after the first task and wait for resumption to deliver the punchline.
await inspiring_joke()
> "a raft of ducks walk into a bar..."
Paused flow runs can be resumed by clicking the Resume button in the Prefect UI or calling the resume_flow_run utility via client code.
resume_flow_run(FLOW_RUN_ID)
The paused flow run will then finish!
> "it's a wonder none of them ducked!"
Suspending a flow run¶
Similar to pausing a flow run, Prefect enables suspending an in-progress flow run.
The difference between pausing and suspending a flow run
There is an important difference between pausing and suspending a flow run. When you pause a flow run, the flow code is still running but is blocked until someone resumes the flow. This is not the case with suspending a flow run! When you suspend a flow run, the flow exits completely and the infrastructure running it (e.g., a Kubernetes Job) tears down.
This means that you can suspend flow runs to save costs instead of paying for long-running infrastructure. However, when the flow run resumes, the flow code will execute again from the beginning of the flow, so you should use tasks and task caching to avoid recomputing expensive operations.
Prefect exposes this functionality via the suspend_flow_run and resume_flow_run functions, as well as the Prefect UI.
When called inside of a flow suspend_flow_run will immediately suspend execution of the flow run.
The flow run will be marked as Suspended and will not be resumed until resume_flow_run is called.
Timeouts
Suspended flow runs time out after one hour by default.
After the timeout, the flow run will fail with a message saying it suspended and never resumed.
You can specify a different timeout period in seconds using the timeout parameter or pass timeout=None for no timeout.
Here is an example of a flow that does not block flow execution while paused. This flow will exit after one task, and will be rescheduled upon resuming. The stored result of the first task is retrieved instead of being rerun.
from prefect import flow, pause_flow_run, task
@task(persist_result=True)
def foo():
return 42
@flow(persist_result=True)
def noblock_pausing():
x = foo.submit()
pause_flow_run(timeout=30, reschedule=True)
y = foo.submit()
z = foo(wait_for=[x])
alpha = foo(wait_for=[y])
omega = foo(wait_for=[x, y])
Flow runs can be suspended out-of-process by calling suspend_flow_run(flow_run_id=<ID>) or selecting the Suspend button in the Prefect UI or Prefect Cloud.
Suspended flow runs can be resumed by clicking the Resume button in the Prefect UI or calling the resume_flow_run utility via client code.
resume_flow_run(FLOW_RUN_ID)
Subflows can't be suspended independently of their parent run
You can't suspend a subflow run independently of its parent flow run.
If you use a flow to schedule a flow run with run_deployment, the
scheduled flow run will be linked to the calling flow as a subflow run by
default. This means you won't be able to suspend the scheduled flow run
independently of the calling flow. Call run_deployment with
as_subflow=False to disable this linking if you need to be able to suspend
the scheduled flow run independently of the calling flow.
Waiting for input when pausing or suspending a flow run¶
Experimental
The wait_for_input parameter used in the pause_flow_run or suspend_flow_run functions is an experimental feature.
The interface or behavior of this feature may change without warning in future releases.
If you encounter any issues, please let us know in Slack or with a Github issue.
When pausing or suspending a flow run you may want to wait for input from a user.
Prefect provides a way to do this by leveraging the pause_flow_run and suspend_flow_run functions.
These functions accept a wait_for_input argument, the value of which should be a subclass of prefect.input.RunInput, a pydantic model.
When resuming the flow run, users are required to provide data for this model. Upon successful validation, the flow run resumes, and the return value of the pause_flow_run or suspend_flow_run is an instance of the model containing the provided data.
Here is an example of a flow that pauses and waits for input from a user:
from prefect import flow, pause_flow_run
from prefect.input import RunInput
class UserNameInput(RunInput):
name: str
@flow(log_prints=True)
async def greet_user():
user_input = await pause_flow_run(
wait_for_input=UserNameInput
)
print(f"Hello, {user_input.name}!")
Running this flow will create a flow run. The flow run will advance until code execution reaches pause_flow_run, at which point it will move into a Paused state.
Execution will block and wait for resumption.
When resuming the flow run, users will be prompted to provide a value for the name field of the UserNameInput model.
Upon successful validation, the flow run will resume, and the return value of the pause_flow_run will be an instance of the UserNameInput model containing the provided data.
For more in-depth information on receiving input from users when pausing and suspending flow runs, see the Creating interactive workflows guide.
Canceling a flow run¶
You may cancel a scheduled or in-progress flow run from the CLI, UI, REST API, or Python client.
When cancellation is requested, the flow run is moved to a "Cancelling" state. If the deployment is a work pool-based deployemnt with a worker, then the worker monitors the state of flow runs and detects that cancellation has been requested. The worker then sends a signal to the flow run infrastructure, requesting termination of the run. If the run does not terminate after a grace period (default of 30 seconds), the infrastructure will be killed, ensuring the flow run exits.
A deployment is required
Flow run cancellation requires the flow run to be associated with a deployment.
A monitoring process must be running to enforce the cancellation.
Inline subflow runs, i.e. those created without run_deployment, cannot be cancelled without cancelling the parent flow run.
If you may need to cancel a subflow run independent of its parent flow run, we recommend deploying it separately and starting it using the run_deployment function.
Cancellation is robust to restarts of Prefect workers.
To enable this, we attach metadata about the created infrastructure to the flow run.
Internally, this is referred to as the infrastructure_pid or infrastructure identifier.
Generally, this is composed of two parts:
- Scope: identifying where the infrastructure is running.
- ID: a unique identifier for the infrastructure within the scope.
The scope is used to ensure that Prefect does not kill the wrong infrastructure. For example, workers running on multiple machines may have overlapping process IDs but should not have a matching scope.
The identifiers for infrastructure types:
- Processes: The machine hostname and the PID.
- Docker Containers: The Docker API URL and container ID.
- Kubernetes Jobs: The Kubernetes cluster name and the job name.
While the cancellation process is robust, there are a few issues than can occur:
- If the infrastructure block for the flow run has been removed or altered, cancellation may not work.
- If the infrastructure block for the flow run does not have support for cancellation, cancellation will not work.
- If the identifier scope does not match when attempting to cancel a flow run the worker will be unable to cancel the flow run. Another worker may attempt cancellation.
- If the infrastructure associated with the run cannot be found or has already been killed, the worker will mark the flow run as cancelled.
- If the
infrastructre_pidis missing from the flow run will be marked as cancelled but cancellation cannot be enforced. - If the worker runs into an unexpected error during cancellation the flow run may or may not be cancelled depending on where the error occurred. The worker will try again to cancel the flow run. Another worker may attempt cancellation.
Enhanced cancellation
We are working on improving cases where cancellation can fail.
You can try the improved cancellation experience by enabling the PREFECT_EXPERIMENTAL_ENABLE_ENHANCED_CANCELLATION setting on your worker or agents:
prefect config set PREFECT_EXPERIMENTAL_ENABLE_ENHANCED_CANCELLATION=True
If you encounter any issues, please let us know in Slack or with a Github issue.
Cancel via the CLI¶
From the command line in your execution environment, you can cancel a flow run by using the prefect flow-run cancel CLI command, passing the ID of the flow run.
prefect flow-run cancel 'a55a4804-9e3c-4042-8b59-b3b6b7618736'
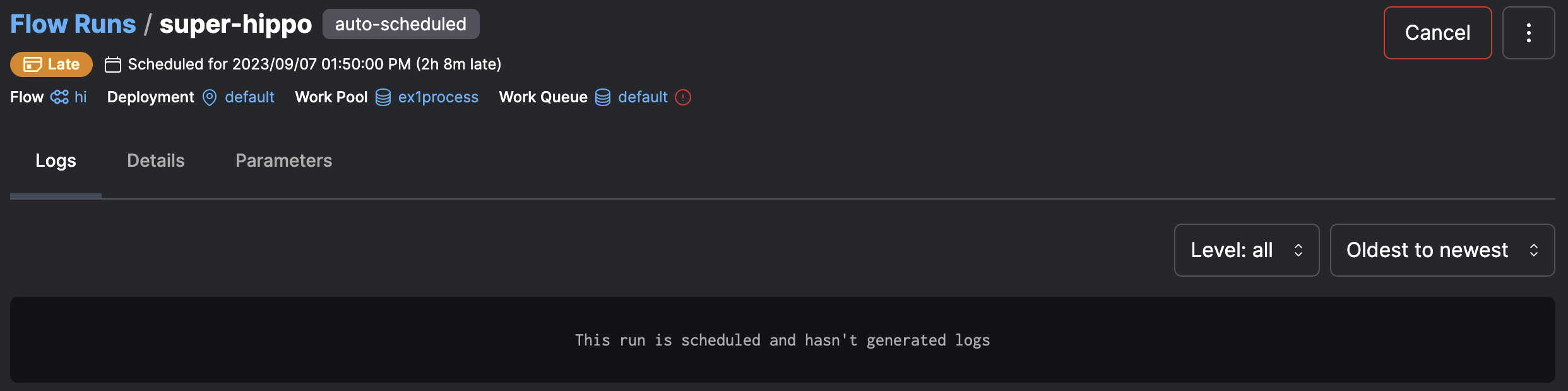
Cancel via the UI¶
From the UI you can cancel a flow run by navigating to the flow run's detail page and clicking the Cancel button in the upper right corner.
Timeouts¶
Flow timeouts are used to prevent unintentional long-running flows. When the duration of execution for a flow exceeds the duration specified in the timeout, a timeout exception will be raised and the flow will be marked as failed. In the UI, the flow will be visibly designated as TimedOut.
Timeout durations are specified using the timeout_seconds keyword argument.
from prefect import flow
import time
@flow(timeout_seconds=1, log_prints=True)
def show_timeouts():
print("I will execute")
time.sleep(5)
print("I will not execute")